Reward-PRPO
Replaces scalarized rewards with dimension-wise relative advantages, preserving discriminative optimization signals for distinct reasoning objectives.



Accepted at ICLR 2026
A unified framework with PRPO for robust multi-dimensional optimization and MCDR-Bench for objective chart deep-research evaluation.
1ByteDance, 2ShanghaiTech University, 3School of Computer Science and Engineering, Sun Yat-sen University
Notes: Work done during internship at ByteDance (Jiajin Tang); project lead: Gaoyang; corresponding author: Sibei Yang.
We target chart deep research, where models must go beyond visual QA and produce reliable analytical reasoning. PRPO performs parallel optimization across reward dimensions and capability-aware data partitions, reducing optimization conflicts in RL post-training. MCDR-Bench converts subjective report generation into objective error identification via controlled error injection. Together, they provide a unified framework for training and evaluating deep chart reasoning.
Charts are now central analytical interfaces for discovery and decision support, yet most multimodal systems remain focused on shallow tasks such as chart QA and factual lookup. This work targets chart deep research: end-to-end capability spanning background knowledge integration, fact extraction, relationship construction, report synthesis, and forecast/plan reasoning.
We identify two bottlenecks that systematically constrain this capability. At training time, scalar reward aggregation and heterogeneous data mixing create optimization conflicts. At evaluation time, open-ended report scoring is costly and subjective, preventing reliable large-scale benchmarking.

Main-paper teaser: GRPO suffers from interference-limited exploration, while PRPO decomposes optimization over reward dimensions and capability groups, yielding more effective exploration and stronger final performance.
To address both bottlenecks jointly, we propose Parallel Relative Policy Optimization (PRPO) for training and MCDR-Bench for evaluation. PRPO improves capability development under multi-objective RL post-training, while MCDR-Bench converts subjective generation quality into objective error identification with unique answers.
PRPO addresses two conflict sources together: interference across reward dimensions and imbalance across heterogeneous capability data.
Replaces scalarized rewards with dimension-wise relative advantages, preserving discriminative optimization signals for distinct reasoning objectives.
Partitions training samples by capability type and applies iterative outlier relegation to avoid unstable partition statistics dominating updates.
Integrates reward- and data-parallel optimization to support balanced capability growth for complex chart reasoning.
For response i, reward dimension k, and data partition m, PRPO computes a partition-specific and dimension-specific standardized advantage:
$$\hat{A}_i^{(k,m)} = \frac{R_i^{(k)} - \bar{R}^{(k,m)}}{\sigma^{(k,m)}}$$
This advantage is then injected into a clipped policy objective aggregated over dimensions and partitions:
$$J_{\mathrm{PRPO}}(\theta)=\sum_{m=1}^{M_{\mathrm{final}}}\lambda_m\sum_{k=1}^{K}\lambda_k\,\mathbb{E}\left[\frac{1}{|\mathcal{G}_m|}\sum_{i\in\mathcal{G}_m}\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}L_{\mathrm{clip}}\big(r_{i,t}(\theta),\hat{A}_i^{(k,m)}\big)\right]$$
Compared with scalar-reward GRPO, PRPO preserves cross-dimension signals and avoids blind mixing of heterogeneous data, enabling balanced capability development.

PRPO framework: reward-wise decomposition + capability-wise grouping with iterative outlier relegation.
MCDR-Bench is built around the error uniqueness principle: convert subjective report quality judgment into objective error identification. Evaluation is decomposed into five dimensions: Background Knowledge (BG), Fact Extraction (FE), Relationship Construction (RL), Deep Research (DR), and Forecast/Plan (F/P).
The benchmark follows a two-phase protocol: (1) high-quality deep report generation over complex charts, and (2) targeted error injection to produce fine-grained objective evaluation tasks.

MCDR-Bench framework with five capability stages: background acquisition, fact extraction, relationship construction, deep report generation, and forecast/plan.
Curate complex charts from Dashboard Design Patterns, MME-realworld, ChartQAPRO, and Pew Research, then filter out low-complexity charts.
Retrieve domain context to support grounded interpretation before chart-level reasoning.
Extract atomic facts and organize inter-variable relationships as structured evidence for deep analysis.
Generate comprehensive reports and forward-looking recommendations with human quality checks on critical stages.
Inject BG/FE/RL/DR/F/P errors to convert subjective generation quality into objective error identification over 3,084 hard samples.
1,021
High-complexity charts curated
3,084
Error-injected evaluation samples
10k
RL training samples with capability labels
| Setting | BG | FE | RL | DR | F/P | Overall | Mean | Gain vs. GRPO |
|---|---|---|---|---|---|---|---|---|
| GRPO | 41.24 | 51.69 | 75.38 | 66.14 | 77.40 | 61.71 | 62.26 | - |
| PRPO | 50.65 | 61.38 | 81.78 | 72.83 | 84.01 | 69.62 | 69.90 | +7.64 |
| GRPO (Think) | 43.13 | 48.77 | 77.75 | 70.28 | 81.02 | 63.00 | 63.99 | - |
| PRPO (Think) | 62.90 | 65.23 | 88.87 | 80.91 | 87.21 | 76.26 | 76.89 | +12.90 |
| Model | Factoid | MCQ | Conv. | FactChk | Hypo. | Overall | Mean |
|---|---|---|---|---|---|---|---|
| Qwen2.5-VL-7B-Instruct | 27.49 | 37.85 | 55.22 | 46.72 | 44.40 | 36.31 | 41.33 |
| + PRPO | 36.24 | 50.47 | 49.63 | 53.28 | 53.69 | 42.95 | 47.69 |

The trajectory comparison shows that PRPO expands exploration early and maintains stronger convergence stability later. This behavior is consistent with the method design: reward-wise decomposition preserves discriminative optimization signals, while capability-wise grouping reduces gradient conflicts across heterogeneous samples.
In practice, this translates to better optimization efficiency and more robust multi-capability performance than scalarized GRPO training.
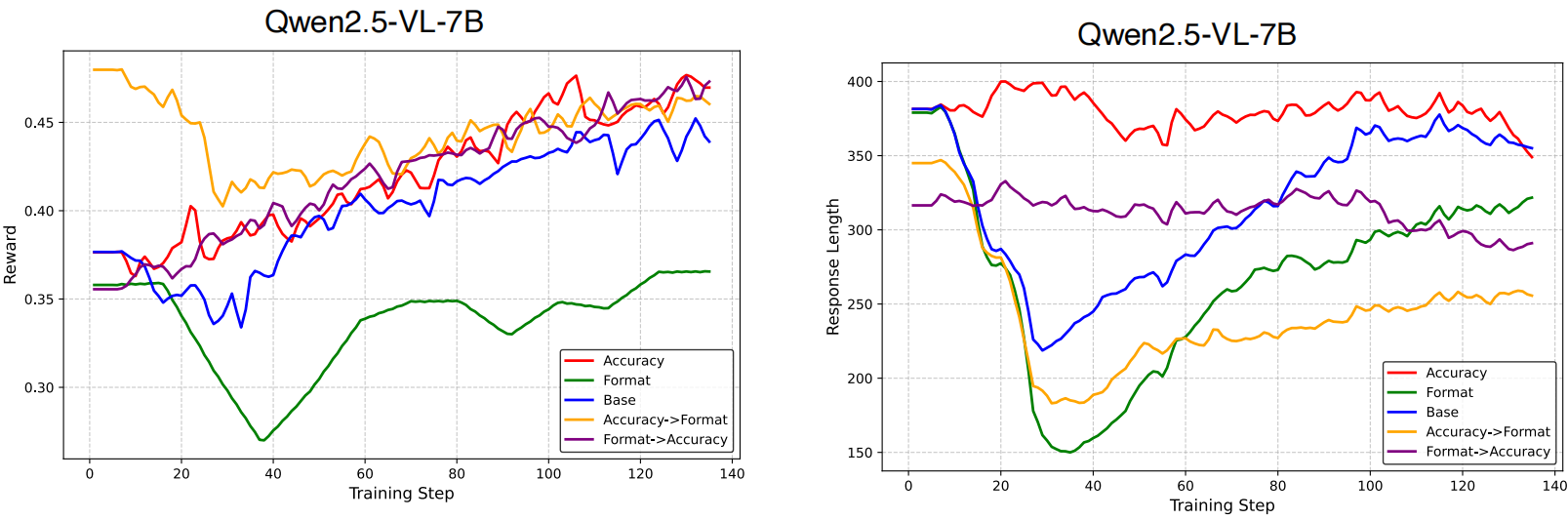
Additional quantitative evidence from the paper: PRPO consistently improves overall performance and remains stable under heterogeneous training composition.
arXiv preprint is available.
arXiv: 2603.06677v1Codes and training scripts.
GitHubMCDR-Bench and evaluation toolkit.
Coming soon@inproceedings{prpo2026,
title={Chart Deep Research in LVLMs via Parallel Relative Policy Optimization},
author={Jiajin Tang and Gaoyang and Wenjie Wang and Sibei Yang and Xing Chen},
booktitle={International Conference on Learning Representations},
year={2026}
}